Pythonでバイナリファイルを読んでみよう(後編)

Photo by Nagara Oyodo on Unsplash
本記事の内容
Python でバイナリファイルを読む方法を紹介する。 具体的には、WAV(Waveform Audio File Format)ファイルから、サンプリングレートと時系列データを取得することを目指す。
本記事は後編にあたる。前編はこちら。
目次
(前編) 1 WAV ファイルの作成 2 WAV ファイルのフォーマットについて大まかに説明 3 バイナリモードでファイルを開く 4 バイナリファイルのランダムアクセス
(後編) 1 WAV ファイルの準備 2 WAV ファイルのフォーマットについて 3 サンプリングレートと時系列データをバイト列で取得 4 バイト列を int に変換 5 バイト列を ndarray に変換 6 WAV ファイルから、サンプリングレートと時系列データを取得
1. WAV ファイルの準備
今回も、前編で作成した WAV ファイル(new_file.wav)を使用する。 確認のため、pysoundfile を用いて、WAV ファイルのサンプリングレートと時系列データを調べる。
import numpy as np
import matplotlib.pyplot as plt
import soundfile as sf # WAVファイルの読み書きに使用
# WAVファイルを読み込む
sampling_data, sampling_rate = sf.read('new_file.wav')
time = np.arange(start=0, stop=len(sampling_data)/sampling_rate, step=1/sampling_rate)
print(f'sampling_data = {sampling_data}')
print(f'sampling_rate = {sampling_rate} [Hz]')
# プロットする
fig, ax = plt.subplots()
ax.plot(time, sampling_data)
ax.set_xlabel('time')
ax.set_ylabel('amplitude')
fig.show()sampling_data = [ 0. 0.00097656 0.00198364 ... -0.54150391 -0.5423584 -0.54318237]
sampling_rate = 1000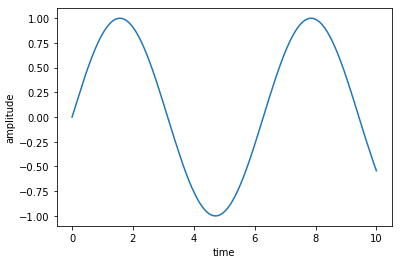 出力結果。
出力結果。
時系列データとサンプリングレートが格納されていることがわかる。 これを、pysoundfile を用いず、取得できるようになることを目指す。
2. WAV ファイルのフォーマットについて
WAV ファイルのフォーマットについては、これらを参考にした。
- WAV - Wikipedia
- 音ファイル(拡張子:WAVファイル)のデータ構造について - 福岡・東京のシステム開発会社 (株)ユーフィット
- WAV - Waveform Audio File Format
作成した WAV ファイル(new_file.wav)を、バイナリエディタで開いてみる。
ブラウザなら、こちらが便利。
開いてみると、こんな感じ。
 (出所:https://www.oh-benri-tools.com/tools/programming/hex-editor )WAV ファイル(new_file.wav)を開いた状態。
(出所:https://www.oh-benri-tools.com/tools/programming/hex-editor )WAV ファイル(new_file.wav)を開いた状態。
エディタ上では、以下の 4 つのチャンク ID が確認できる。
| byte | チャンク ID(4 文字固定) |
|---|---|
| 1-4 | RIFF |
| 9-12 | WAVE |
| 13-16 | fmt |
| 37-40 | data |
今回は、サンプリングレートと時系列データを取得するのが目的であるが、 fmtチャンクに、サンプリングレート等フォーマットに関する情報が、 dataチャンクに、時系列データが入っているらしい。
というわけで、fmt チャンクと data チャンクの詳細をみていく。 なお、値(16 進数表記)は、リトルエンディアン表記である点に注意。
fmt チャンク
| byte 位置 | size | 値(16 進数) | 値 | 説明 |
|---|---|---|---|---|
| 13-16 | 4 | 66 6D 74 20 | ”fmt “ | fmt 識別子。“fmt “で固定 |
| 17-20 | 4 | 10 00 00 00 | 16 | fmt に格納されているデータのサイズ。単位は[byte] |
| 21-22 | 2 | 01 00 | 1 | 音声フォーマット。1: 非圧縮のリニア PCM フォーマット[1] |
| 23-24 | 2 | 01 00 | 1 | チャンネル数。1: モノラル |
| 25-28 | 4 | E8 03 00 00 | 1000 | ★ サンプリング周波数。単位は[Hz] |
| 29-32 | 4 | D0 07 00 00 | 2000 | 1 秒あたりのバイト数。チャンネル数 * 1 サンプルあたりのバイト数 * サンプリングレート |
| 33-34 | 2 | 02 00 | 2 | ブロックサイズ。チャンネル数 * 1 サンプルあたりのバイト数 |
| 35-36 | 2 | 10 00 | 16 | ☆ 1 サンプルあたりのビット数。16 bit = 2 byte |
[1] PCM については、こちらをどうぞ。
data チャンク
| byte 位置 | size | 値(16 進数) | 値 | 説明 |
|---|---|---|---|---|
| 37-40 | 4 | 64 61 74 61 | ”fmt “ | data 識別子。“data “で固定 |
| 41-44 | 4 | 20 4E 00 00 | 20000 | ☆ data に格納されているデータのサイズ。単位は[byte] |
| 45-20044 | 20000 | 00 00 20 00 … | [0, 32, …] | ★ 時系列データ。今回 1 サンプルあたり 16 bit なので、符号あり整数で表現される。 |
★ が、今回読み取るデータ、 ☆ が、読み取り前に確認しておくべきデータである。
3. サンプリングレートと時系列データをバイト列で取得
前編で紹介したように、ランダムアクセスでバイナリファイルを読み込み、 サンプリングレートと時系列データをバイト列で取得する。
import os
with open('new_file.wav', mode="rb") as fin:
fin.seek(24, os.SEEK_CUR)
sampling_rate_bytes = fin.read(4) # 25-28 byte: サンプリングレート
fin.seek(16, os.SEEK_CUR)
sampling_data_bytes = fin.read(20000) # 45-20044 byte: 時系列データ
print('変換前')
print(f'sampling_rate_bytes = {sampling_rate_bytes}')
print(f'sampling_data_bytes = {sampling_data_bytes}')変換前
sampling_rate_bytes = b'\xe8\x03\x00\x00'
sampling_data_bytes = b'\x00\x00 \x00A\x00b\x00\x83\x00\xa3\x00\xc4\x00\xe5\x00\x06\x01&\x01G\x01h\x01\x89\x01\xa9\x01\xca\x01\xeb\x01\x0c\x02-\x02M\x02n\x02\x8f\x02\xb0\x02\xd0\x02\xf1\x02\x12\x033\x03S\x03t\x03\x95\x03\xb6\x03\xd6 ...(省略)'あとはこれらを適宜 int 型等に変換すればオッケーである。
4. バイト列を int に変換
サンプリングレートは 整数値で格納されているので、int 型に変換することになる。
変換には、主に 2 種類の方法がある。
int.from_bytes(bytes, byteorder, *, signed=False)
struct.unpack(format, buffer)
上記2種類の方法で、サンプリングレートを int 型に変換してみる。
import struct
sampling_rate_bytes = b'\xe8\x03\x00\x00'
print('変換前')
print(f'sampling_rate_bytes = {sampling_rate_bytes}')
# リトルエンディアン、4バイトの符号なし整数に変換する
# 方法1
sampling_rate_int1 = int.from_bytes(sampling_rate_bytes, byteorder='little', signed=False)
# 方法2
# '<'がリトルエンディアン、'i'が4バイトの符号なし整数を意味する
sampling_rate_int2 = struct.unpack('<i', sampling_rate_bytes)
print()
print('変換後')
print(f'sampling_rate_int1 = {sampling_rate_int1}')
print(f'sampling_rate_int2 = {sampling_rate_int2}')
print(f'sampling_rate_int2[0] = {sampling_rate_int2[0]}')変換前
sampling_rate_bytes = b'\xe8\x03\x00\x00'
変換後
sampling_rate_int1 = 1000
sampling_rate_int2 = (1000,)
sampling_rate_int2[0] = 1000基本的に前者のint.to_bytes()を使えば十分である。
後者のstruct.unpack()は、値が tuple 型で返ってくることからわかるように、複数の値を同時に変換することが可能である。また、書式指定文字(引数の<h部)を変えることで float 型への変換も可能である。
5. バイト列を ndarray に変換
時系列データも整数値で格納されているが、 後の処理などを考えると、ndarray で取得するのが最も扱いやすいだろう。
numpy.frombuffer(buffer, dtype=float, count=- 1, offset=0, *, like=None)で、一次元の ndarray に直接変換することができる。
import numpy as np
sampling_data_bytes = b'\x00\x00 \x00A\x00b\x00\x83\x00\xa3\x00\xc4\x00\xe5\x00\x06\x01&\x01G\x01h\x01\x89\x01\xa9\x01\xca\x01\xeb\x01\x0c\x02-\x02M\x02n\x02\x8f\x02\xb0\x02\xd0\x02\xf1\x02\x12\x033\x03S\x03t\x03\x95\x03\xb6\x03\xd6 ...(省略)'
print('変換前')
print(f'sampling_data_bytes = {sampling_data_bytes}')
# バイト列を ndarray に変換する
# '<'がリトルエンディアン、'i2'が2バイトのintegerを意味する
sampling_data = np.frombuffer(sampling_data_bytes, dtype='<i2')
print()
print('変換後')
print(f'sampling_data = {sampling_data}')
print(f'sampling_data type : {type(sampling_data)}')
変換前
sampling_data_bytes = b'\x00\x00 \x00A\x00b\x00\x83\x00\xa3\x00\xc4\x00\xe5\x00\x06\x01&\x01G\x01h\x01\x89\x01\xa9\x01\xca\x01\xeb\x01\x0c\x02-\x02M\x02n\x02\x8f\x02\xb0\x02\xd0\x02\xf1\x02\x12\x033\x03S\x03t\x03\x95\x03\xb6\x03\xd6 ...(省略)'
変換後
sampling_data = [ 0 32 65 ... -17744 -17772 -17799]
sampling_data type : <class 'numpy.ndarray'>dtypeの指定で、float にも、integer にも変換可能である。
6. WAV ファイルから、サンプリングレートと時系列データを取得
最終的なコードは、こんな感じ。
import os
import numpy as np
import matplotlib.pyplot as plt
# バイナリモードでファイルを開く
with open('new_file.wav', mode="rb") as fin:
fin.seek(24, os.SEEK_CUR)
sampling_rate_bytes = fin.read(4) # 25-28 byte: サンプリングレート
fin.seek(16, os.SEEK_CUR)
sampling_data_bytes = fin.read(20000) # 45-20044 byte: 時系列データ
# バイト列からint型に変換
sampling_rate = int.from_bytes(sampling_rate_bytes, byteorder='little', signed=False)
# バイト列からndarrayに変換
sampling_data = np.frombuffer(sampling_data_bytes, '<i2')
print(f'sampling_rate = {sampling_rate} [Hz]')
print(f'sampling_data = {sampling_data}')
# プロットする
time = np.arange(start=0, stop=len(sampling_data)/sampling_rate, step=1/sampling_rate)
fig, ax = plt.subplots()
ax.plot(time, sampling_data)
ax.set_xlabel('time')
ax.set_ylabel('amplitude')
fig.show()sampling_rate = 1000 [Hz]
sampling_data = [ 0 32 65 ... -17744 -17772 -17799]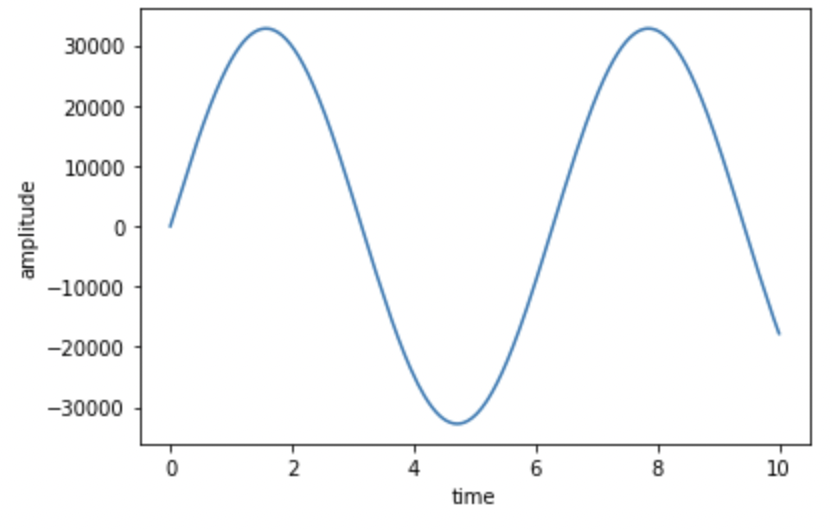 出力結果。
出力結果。
今日のまとめ
バイト列を int に変換
int.from_bytes(bytes, byteorder, *, signed=False)または、struct.unpack(format, buffer)の2種類がある。
struct.unpack(format, buffer)は、書式指定文字を変えることで float 型への変換も可能。
import struct
data_bytes = b'\xe8\x03\x00\x00'
data_to_int1 = int.from_bytes(byte, byteorder='little', signed=False)
# '<'がリトルエンディアン、'i'が4バイトの符号なし整数を意味する
data_to_int2 = struct.unpack('<i', sampling_rate_bytes)バイト列を ndarray に変換
numpy.frombuffer(buffer, dtype=float, count=- 1, offset=0, *, like=None)を用いる。
import numpy as np
data_bytes = b'\x00\x00 \x00A\x00b\x00\x83\x00\xa3\x00\xc4\x00\xe5\x00\x06\x01&\x01G\x01h\x01\x89\x01\xa9\x01\xca\x01\xeb\x01\x0c\x02-\x02M\x02n\x02\x8f\x02\xb0\x02\xd0\x02\xf1\x02\x12\x033\x03S\x03t\x03\x95\x03\xb6\x03\xd6 ...(省略)'
# '<'がリトルエンディアン、'i2'が2バイトのintegerを意味する
data_to_ndarray = np.frombuffer(data_bytes, '<i2')